
The Day After Mythos


At the end of March, a misconfigured CMS at frontier AI lab Anthropic leaked the details of a new model, Mythos. Ironically given the way that the model was revealed, Anthropic’s announcement was not that a new model was being released—it was instead an announcement that the model’s capabilities made it too dangerous to release right away. Instead, Anthropic stood up an effort to harden critical internet infrastructure against the cybersecurity capabilities they predicted would soon come to open models, Project Glasswing.
An initial version of this new model, called Mythos Preview, was shared with a group of companies that included Mozilla, Broadcom, Apple and Palo Alto Networks. Last week, this group was expanded. There was, to Anthropic’s surprise, another group also using Mythos Preview in early April: a private Discord server of AI researchers and enthusiasts obtained unauthorized access to the model by guessing, based on past leaks, where to send their API calls.
Mythos Preview has also been in use internally at Anthropic, to such great effect that it seems to have prompted a recent piece from Anthropic reflecting on the path to Recursive Self Improvement—a term coined in the mid-twentieth century and popularized by Eliezer Yudkowsky. Anthropic’s conclusion, later echoed by OpenAI, was that the likely future speed of AI research was such that a pause in model capability development would be a good idea, if it were possible.
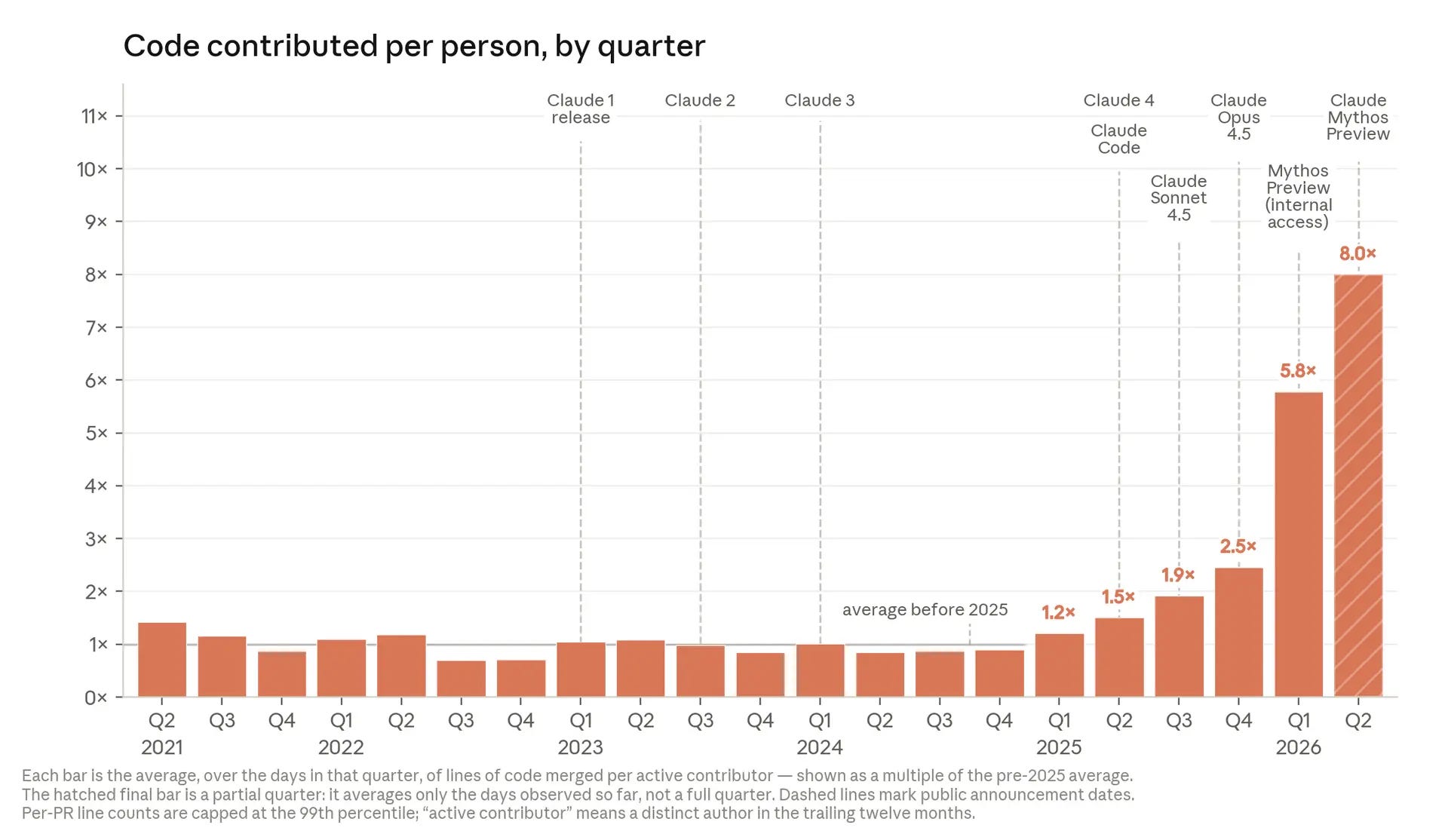
Here there is already the making of a 21st century Greek myth. Not for nothing was the model class christened Mythos. The post-frontier AI model, which exhibits such advanced cybersecurity capabilities that it can’t be released to the public, is leaked to the public through an insecure CMS and taken for joyrides by Discord cyberpunks.
The frontier lab regarded by many as the only truly AGI-pilled lab trains a model so useful for advancing AI research that it inspires reflections on RSI (and the sentence: “In this world, the pace of progress in AI development becomes determined entirely by the availability of compute”) in the same month that the CEO, Dario Amodei, tells Dwarkesh Patel that he chose to be conservative about investments in compute because he did not want to bet the firm. Weeks after Mythos is trained, Anthropic is designated a supply chain risk by the DoW and then, days before the release of the model to the public, reports emerge that the NSA is preparing to use Mythos in offensive cyber operations.

What are we to make of this? There are some who see in the story of Mythos a hubris that does not bode well for the future. Some saw in the decision to hold the model back for safety reasons either marketing spin or misdirection away from compute shortages. I’m not so sure.
Cards on the table: I am inclined to take Anthropic at face value here. I am inclined to believe that many people within Anthropic, from the junior researchers to the founding team, share an earnest belief in both the possibilities and the risks of the technology they are working to advance. I am inclined to think that it is an awareness of both, rather than a cynical deployment of one in pursuit of another, that leads to what might appear to be a contradiction between Anthropic’s ideals and their actions.
Which is significant, because today Anthropic released the first Mythos-class model to the public, Fable 5. And there are a few things that you could be cynical about, if you were that way inclined.
Day 1s and N-days
But first: is Fable 5 a good model? It sure looks like it.






(But not like, perfect or anything)


Anthropic researchers have emphasized two things about the model: 1) Fable 5 is just Mythos with guardrails, and 2) it’s state-of-the-art on every capability, with a particular advantage in autonomous, long time-horizon tasks.
OpenAI co-founder and now-Anthropic employee Andrej Karpathy said this:
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon’s paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything!
If you are simply interested in understanding how capable Fable 5 is, you can stop here. The Anthropic announcement post goes into more detail, but the model is very good. OpenAI will likely release a model that is better on some measures and maybe not as good on others. Deepmind might surprise us. The long road of technological diffusion and trying very hard to make GDP growth go up still lies before us.
But the release of Fable 5 does have some broader implications.
Logan Graham, who heads the Frontier Red Team at Anthropic, emphasized a few things that I found interesting. The first was the importance of getting the model, and presumably particularly the latest Mythos checkpoint that lacks Fable’s cybersec safeguards, to cybersecurity teams. This is no surprise—that was, after all, the guiding philosophy behind Glasswing. But he also said that there is no longer a clear delineation between AI alignment and cybersecurity. (Foreshadowing.)
For a blog post released yesterday, the Red Team pointed Anthropic’s models at patch notes for software and had them attempt to reverse engineer the vulnerabilities and produce working exploits. Here we start seeing some real separation between the models. Within 12 hours of being shown the patch notes and with a 3 million token budget, Mythos Preview recreated 8 working exploits. Six of those were produced within the first six hours.
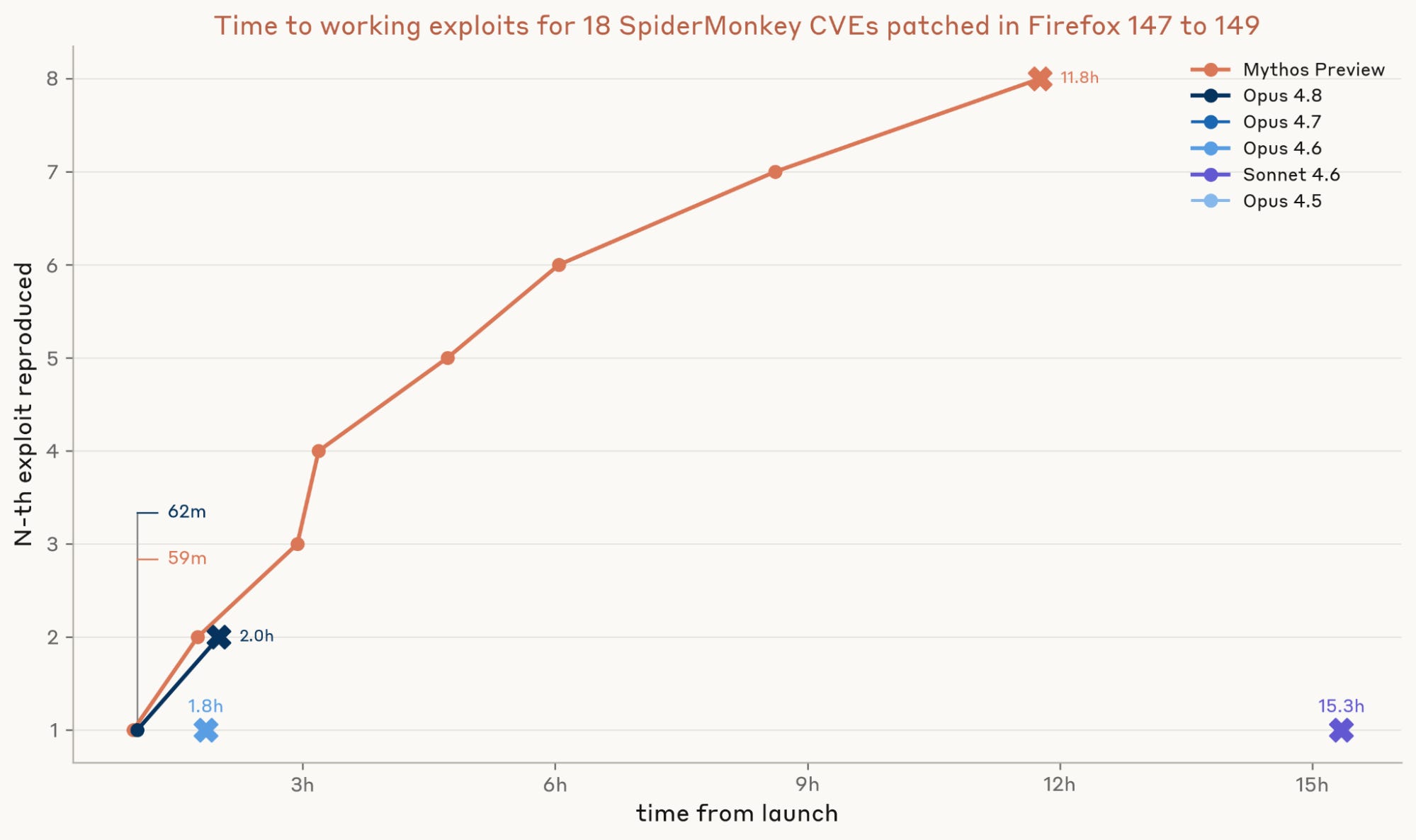
I’ll defer here to the Red Team on the implications:
It’s not surprising that today’s language models can produce N-day exploits. Given enough time and a good enough harness, this has likely been possible for a while.
But with models like Mythos Preview, what has changed is the volume of findings and the speed with which they can be produced. A lone operator can now turn a month’s worth of patches into working exploits in a single afternoon—for a few thousand dollars and with no specialized expertise.
This means that the typical patching playbook that software developers use today—with monthly release cadences, multi-week staged rollouts, and a lag between pre-release and stable channels—no longer holds. It was built on the assumption that weaponizing a patch takes expert-weeks (and that there was a limited pool of experts capable of doing so). But “N-day” has become dangerously misleading. N-hour is closer to the reality we now operate in.
Mythos Preview, however, is reserved only for trusted partners and Anthropic insiders. The rest of us have just been granted access to Fable 5. How does it fare on cybersecurity challenges? Well…


If you’re a known cybersecurity researcher whose Claude history contains evidence of cybersecurity work, just saying “Hi!” to Fable 5 is enough to trigger safeguards and get bumped down to Opus. What about for people who aren’t cybersecurity researchers?
RSI for me but not for thee
Fable 5 includes safeguards on several topics. As we saw above, simply being associated with one of these topics in Claude’s memory is enough to get yourself bumped from SOTA superintelligence to just regular old superintelligence. This is true for cybersecurity, it’s true for biology and chemistry, and it’s true for distillation-related queries.
I should pause briefly to say that this seems very sensible to me. The Mythos-class capability jump looks to touch on types of research that have dangerous applications. For example, from the Fable 5 announcement post:
For example, we tested Mythos 5’s ability to complete a challenging step in designing adeno-associated viruses (AAVs). AAVs are a component for delivering gene therapies, but the same capability, in the wrong hands, could enable the design of dangerous viruses. In this task, various AI models were evaluated on their ability to predict how a genetic modification would impact the assembly of the virus’s outer shell… We did not explicitly train our models to perform this task—and yet Mythos-class models outperformed sophisticated models dedicated to protein tasks.
Oh, ok. That seems bad.
As with the ongoing conversations we have had on MTS about AI and cybersecurity, I don’t want to overstate these risks. Viruses and 0 days are scary and dangerous. But 0 days are not necessarily more dangerous, on a difficulty- and cost-adjusted basis, than, say, supply chain attacks.
And, although I’ll avoid spelling them out here, I think there are many lower-hanging fruit for people looking to cause harm to humans than using Mythos to engineer an AAV. But it does seem prudent to hold back these capabilities from general release, at least until we are really, really sure about it. Certainly from Anthropic’s perspective it makes sense to be the “cautious frontier lab who released a hog-tied model” rather than the “move fast and break things but smallpox” frontier lab.
Even the distillation-prevention safeguards make sense to me.
But there is also a form of safeguard that Anthropic does not call out in their launch post.



If you trip the bio or the cybersecurity or the distillation safeguards, you get a nice little message telling you that you have tripped the safeguard and noting that your superintelligence has been downgraded. If you trip the AI research safeguard, you don’t get a notification. Instead, Anthropic will secretly throttle your access. They will fiddle with your prompts on the back end. And this will be invisible to you, the user, except that helpful, enthusiastic Claude will suddenly become rather hapless.


He who rides the tiger finds it hard to get off
Here we find ourselves returning to what I called above the apparent contradiction between Anthropic’s ideals and their actions.
First, the benefit of the doubt. If you are someone who believes, and has good evidence to believe, that Mythos-level capabilities present a significant threat to society absent safeguards, then it makes sense to hold back those capabilities you think might be most dangerous. And if you believe that the ability to train a Mythos-class model is, in the obvious sense, the ne plus ultra of safety threats, then there is no point in placing safeguards on cybersecurity questions unless you also place safeguards on the ability to train a Mythos-class model.
I paraphrased Logan Graham above as saying that there is now no longer a meaningful delineation between AI alignment and cybersecurity. If you extend this reasoning, you could find yourself saying things like: there is no longer a meaningful delineation between AI research and AI alignment. A model capable of advancing AI research is also definitionally capable of facilitating the creation of an unsafe model, and is therefore itself unsafe.
Ah, but this places us in a bit of a jam. Anthropic themselves use a model with no such safeguards. In fact, they just shared a post in which they said that Mythos was accelerating the pace of their own research and pointing towards a future of recursive self improvement! Notably, there is no Project Glasswing for open source AI researchers who are trusted by Anthropic to use Mythos responsibly. There are 100+ organizations who get access to super hacker Claude. Surely there are a handful of people who could be trusted to use pre-training pipeline Claude?
And—although again I should stress that I personally believe Anthropic when they speak to their values—why should we trust Anthropic alone with the capability to build self-improving AI models, to the exclusion of everyone else? Because they got there first? Because they have demonstrated their responsibility and worthiness through Project Glasswing and through the safeguards placed on Fable 5? Perhaps.
I am skating quickly over great complexity here. Apart from anything else, there are other frontier labs competing with Anthropic and a long tail of AI labs offering more open models several months behind the frontier. There is a kind of winner’s curse at work here that risks saddling Anthropic with responsibilities that the relative performance of their models, even Mythos, do not yet justify.
But Anthropic have now climbed aboard the tiger. They are trying to thread the narrow eye of the needle between proliferation and centralization. And they have found themselves ahead of the competition, at least as far as revenue growth and frontier capabilities are concerned. But positions have shifted before, and they will likely do so again. The precedents they set while they’re ahead may return to haunt them in the future, either in the hands of their competition or on the whiteboards of would-be regulators.
I’m not someone who believes that the stakes are existential. The incredible progress in AI we are now seeing will bring with it enormous benefits that will be widely shared. The possible worlds ahead of us range from good to incredible. But that doesn’t mean there won’t be challenges to come. Let’s see how they handle getting off.

The throttling detail is the one with legs. Once a safety restriction also happens to protect your competitive position, outsiders lose the ability to tell which one they're looking at. Doesn't matter whether Anthropic is sincere, and I lean towards thinking they are. The signal is gone either way. Every safety call they make from here gets read as strategy by half the room, which is a strange own goal for the lab that most wants to be trusted.
I'd put maybe 40% that the silent-degradation piece specifically ends up in front of a regulator within 18 months. Secret product discrimination is the rare AI worry antitrust people actually have tools for.